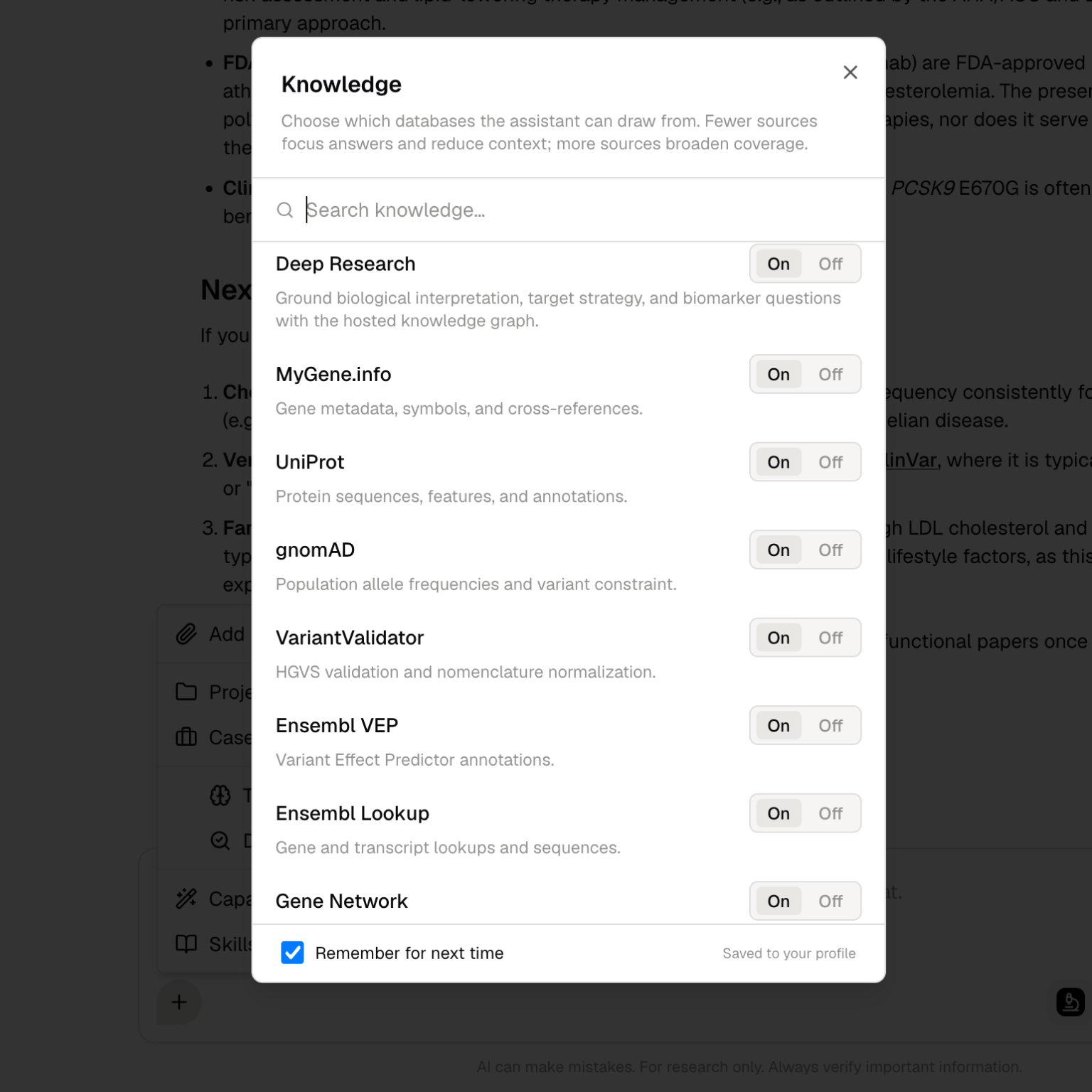
What Deep Research does
Deep Research helps you investigate biological questions across literature, databases, uploaded documents, and connected research context. It can help with:- Literature review and source comparison
- Gene, variant, disease, pathway, protein, and compound research
- Mechanism exploration
- Target and hypothesis assessment
- Evidence summaries for documents or team review
- Source-backed synthesis with explicit weak and strong evidence
- Gap identification and suggested follow-up queries
- Follow-up questions that build on the same research thread
Start a Deep Research run
- Open a chat in Purna.
- Ask a research question that needs source-backed investigation.
- Turn on Deep Research from Preferences, or ask Purna to run Deep Research.
- Review the generated research plan.
- Edit the plan if needed, then click Start to approve it.
- Track the run in the Deep Research panel.
- Review the final answer, evidence table, source list, and gaps.
- Ask follow-up questions or move the synthesis into Scribe Lab.
- “Run Deep Research on the evidence linking PCSK9 inhibition to familial hypercholesterolemia outcomes.”
- “Compare recent evidence for MAPK pathway reactivation as a resistance mechanism in melanoma.”
- “Investigate whether this target has tractability, pathway, disease, and literature support.”
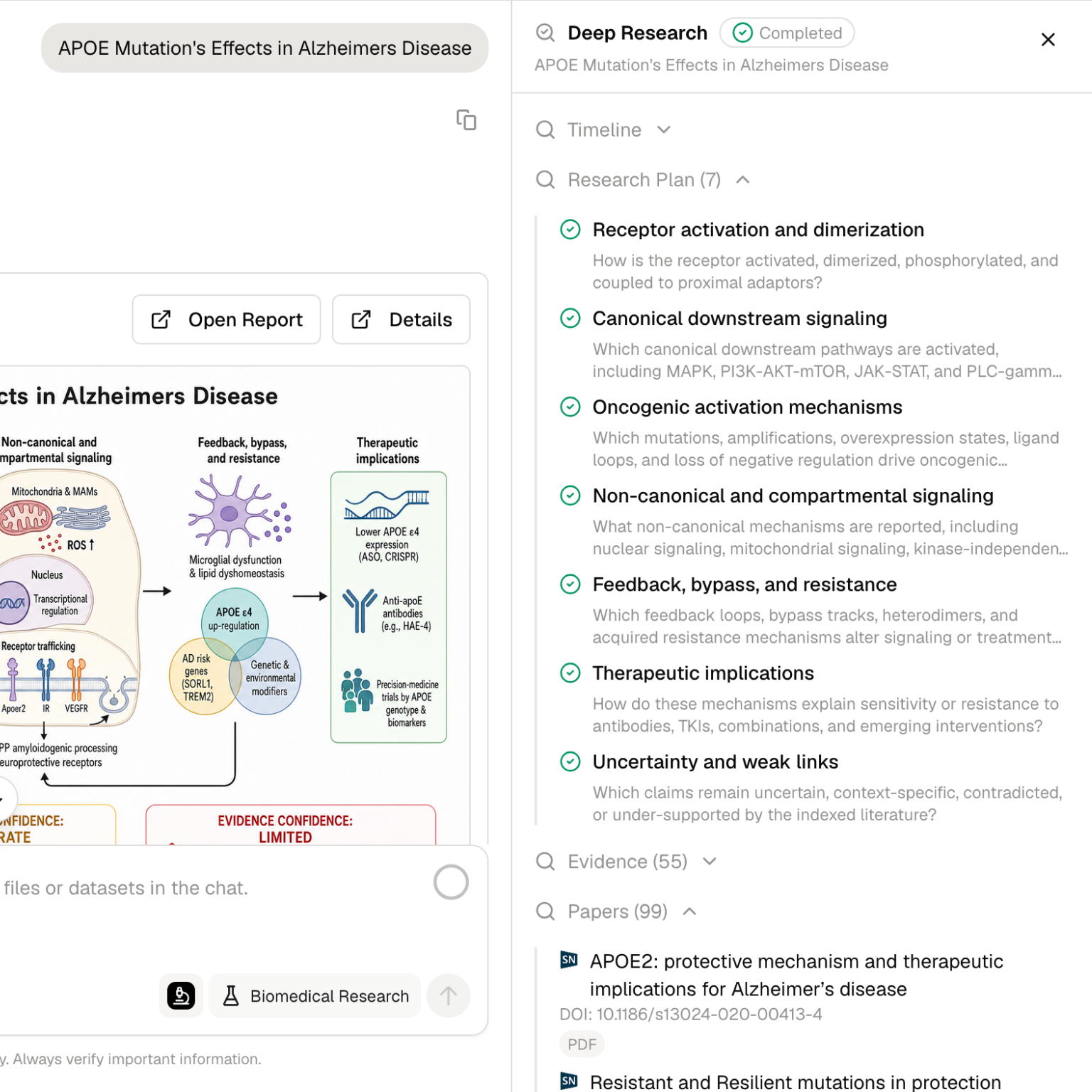
The approval step
Before Deep Research starts, Purna creates a user-approvable research path. This is a research contract, not the final answer. The approval card shows:- Interpreted question: how Purna understands your request
- Domain and question type: the research area and type of investigation
- Research path: the major steps Purna plans to follow
- Candidate review target: how many candidate paper records should be retrieved and abstract-screened before full-text selection
- Review criteria: screening criteria for study types, grey literature, language, age, sex, scope concepts, and exclusions
- Exclusions and red flags: boundaries that should keep the run from drifting outside your intent
Deep Research does not start source acquisition until you approve the plan. This prevents broad or expensive literature runs from starting with the wrong scope.
Candidate review target
The candidate review target controls the breadth of the initial candidate source review. It is not the final full-text download count. Typical targets are:
Free plan runs may be capped at a smaller target.
How it works after approval
After you approve the plan, Deep Research runs as a background job.1
Collect candidate sources
Purna searches candidate literature and source records based on the approved search concepts and review criteria.
2
Screen abstracts
Candidate sources are screened against the approved criteria. Sources can remain awaiting review, be excluded, require full text, or move forward for indexing.
3
Fetch and index full text
Approved full-text sources are fetched and indexed for synthesis when available.
4
Build the structured plan
The run produces a structured plan with research sections and section rationales.
5
Extract evidence
Purna extracts evidence rows, scores evidence when available, attaches provenance, and labels the support signal.
6
Identify gaps
The run records weak links, missing evidence, contradictions, and follow-up questions that would strengthen the analysis.
7
Synthesize the answer
The final answer appears in chat, with source-backed claims and caveats. The side panel remains available for inspection.
Deep Research panel
The Deep Research panel gives you a structured view of the run.Evidence labels
The Evidence tab groups rows by support signal. Labels can vary by result, but common signals include:
Each evidence row can include:
- Claim or evidence axis
- Support label
- Score, when available
- Source excerpt
- Source IDs or citation links
- Provenance back to papers or records
Gaps and weak links
The Gaps tab records places where the research run found an incomplete or fragile conclusion. A gap can represent:- Missing full-text evidence
- Sparse or indirect support
- Contradictory findings across papers
- Lack of the right study type or population
- Missing mechanistic, clinical, structural, or experimental validation
- Claims that need a narrower follow-up search
Sources and citations
Deep Research can use high-authority biological sources such as literature indexes, pathway databases, gene and variant resources, protein databases, compound resources, disease knowledge sources, and uploaded documents. The Sources tab tracks source state during and after the run:- Indexed: source content is available for synthesis
- Awaiting Review: source metadata is captured and waiting for screening
- Needs full text: source looks relevant but requires full-text acquisition
- Excluded: source was screened out, with a reason when available
- Check the cited sources attached to key claims.
- Inspect the support labels in the Evidence tab.
- Review gaps before treating a claim as settled.
- Ask follow-up questions when a source conflict is unclear.
- Move only the relevant conclusions into a document or report.
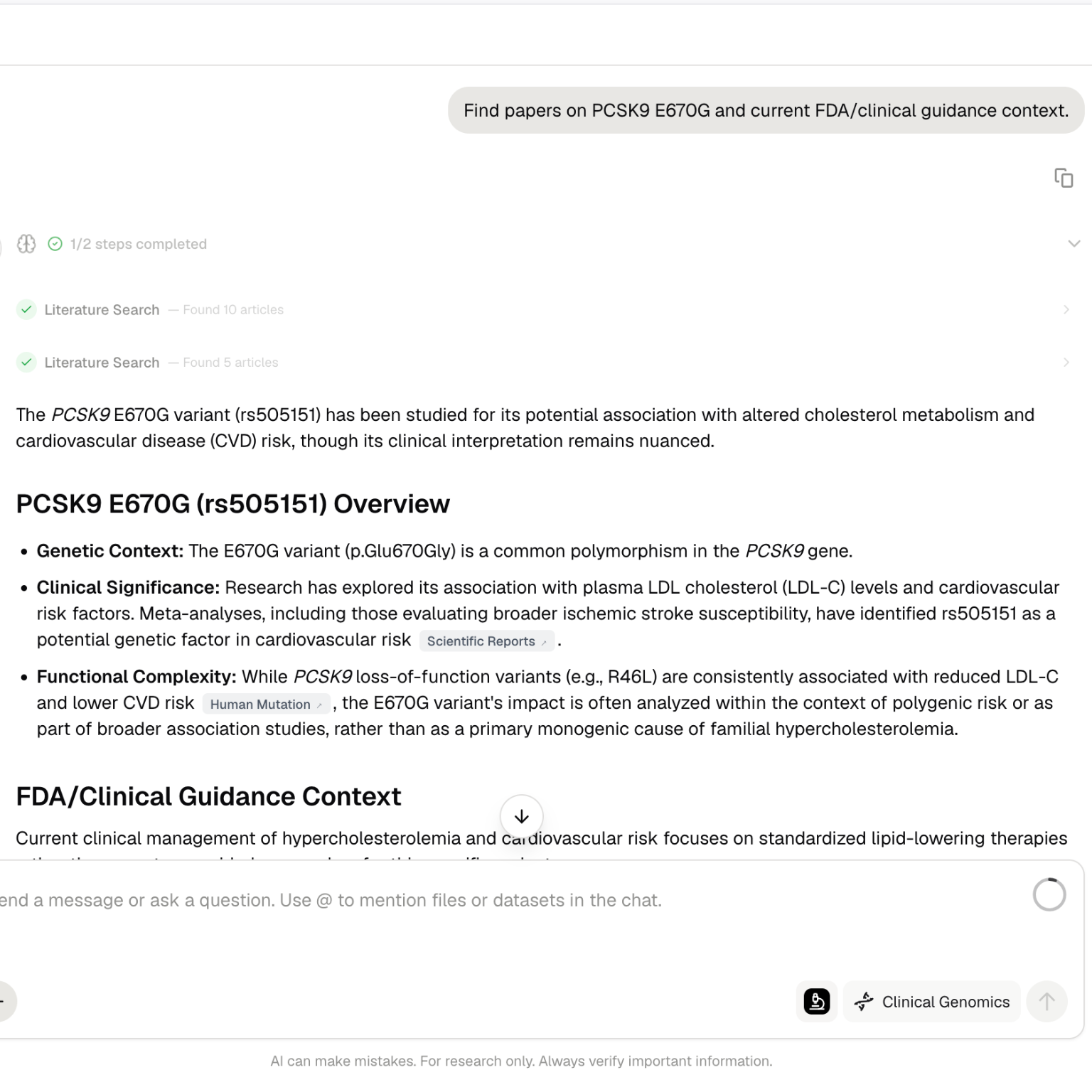
Uploaded documents
If you attach documents in the chat, Deep Research can include those user-provided files in the runtime context. This is useful when you want Purna to consider internal notes, PDFs, spreadsheets, protocols, or source packets alongside public literature. Use@ to reference files explicitly when the run should consider a specific document.
Purna Graph context
Deep Research can use connected biological context from Purna Graph. This helps relate entities such as genes, variants, diseases, proteins, pathways, compounds, and publications. This is useful when the question is not limited to one source. For example, a target assessment may require literature evidence, pathway context, disease associations, structural information, and compound activity.Work with Scribe Lab
Use Scribe Lab when a Deep Research answer needs to become a durable document. A common workflow is:- Run Deep Research on the question.
- Approve or revise the research plan.
- Review the sources, evidence, and gaps.
- Ask for a structured outline or brief.
- Move the material into Scribe Lab.
- Edit the document and preserve source-backed claims.
Best practices
- Ask a focused research question.
- Include the organism, disease area, gene, pathway, target, dataset, or source files when relevant.
- Review the plan before clicking Start.
- Adjust candidate review target and screening criteria when scope matters.
- Specify whether you want a table, brief, comparison, or citation-backed narrative.
- Ask Deep Research to separate strong evidence, weak evidence, and contradictions.
- Check the Gaps tab before treating a conclusion as settled.
- Use follow-up questions to narrow broad findings.
Deep Research supports source-grounded investigation, but it does not replace expert scientific review. Verify important claims before making research, clinical, regulatory, or investment decisions.